
Global Temperature Predictions
Contents
Global Temperature Predictions#
This section uses global temperature data combined with global \(\text{CO}_2\) concentration and warming data provided by the IPCC to compare a simple model with Global warming estimates laid out in the Special Report on Emission Scenarios(SRES)[NAD+00].
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
File ~/Documents/Work/CDS_book/book/lib/python3.10/site-packages/matplotlib/style/core.py:127, in use(style)
126 try:
--> 127 rc = rc_params_from_file(style, use_default_template=False)
128 _apply_style(rc)
File ~/Documents/Work/CDS_book/book/lib/python3.10/site-packages/matplotlib/__init__.py:852, in rc_params_from_file(fname, fail_on_error, use_default_template)
838 """
839 Construct a `RcParams` from file *fname*.
840
(...)
850 parameters specified in the file. (Useful for updating dicts.)
851 """
--> 852 config_from_file = _rc_params_in_file(fname, fail_on_error=fail_on_error)
854 if not use_default_template:
File ~/Documents/Work/CDS_book/book/lib/python3.10/site-packages/matplotlib/__init__.py:778, in _rc_params_in_file(fname, transform, fail_on_error)
777 rc_temp = {}
--> 778 with _open_file_or_url(fname) as fd:
779 try:
File /usr/lib/python3.10/contextlib.py:135, in _GeneratorContextManager.__enter__(self)
134 try:
--> 135 return next(self.gen)
136 except StopIteration:
File ~/Documents/Work/CDS_book/book/lib/python3.10/site-packages/matplotlib/__init__.py:755, in _open_file_or_url(fname)
754 encoding = "utf-8"
--> 755 with open(fname, encoding=encoding) as f:
756 yield f
FileNotFoundError: [Errno 2] No such file or directory: '../matplotlibrc'
The above exception was the direct cause of the following exception:
OSError Traceback (most recent call last)
Input In [1], in <cell line: 9>()
7 from scipy import stats
8 import matplotlib as mpl
----> 9 mpl.style.use('../matplotlibrc')
File ~/Documents/Work/CDS_book/book/lib/python3.10/site-packages/matplotlib/style/core.py:130, in use(style)
128 _apply_style(rc)
129 except IOError as err:
--> 130 raise IOError(
131 "{!r} not found in the style library and input is not a "
132 "valid URL or path; see `style.available` for list of "
133 "available styles".format(style)) from err
OSError: '../matplotlibrc' not found in the style library and input is not a valid URL or path; see `style.available` for list of available styles
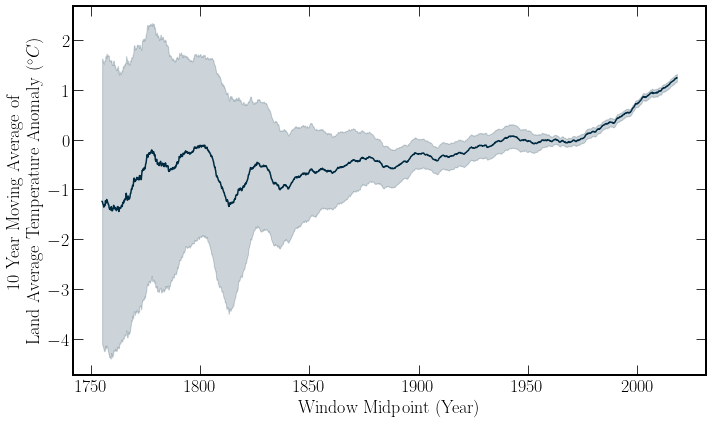
The global Temperature data is taken from Berkley Earth. The temperature data has missing fields as with the Global \(\text{CO}_2\) data. Further, the date is formatted awkwardly into a fixed width table format with commented-out headers. Finally, the global temperature data is seasonal. Thus some data cleaning and formatting is required.
When ananlysing the data, a Fourier-based fit could be applied similarly to that performed in the section on Global \(\text{CO}_2\) data. Because this section is not looking for a functional form, an average is more straightforward to implement.
After cleaning the data of null fields, a moving average can be used to remove the seasonal trends.
| Number of Null Values | |
|---|---|
| year | 0 |
| month | 0 |
| monthly_anomaly | 1 |
| monthly_anomaly_unc | 3 |
| dt | 0 |
#Drop NA
temp_data = temp_data.dropna()
WINDOW = 120
# Sliding window weighted average:
slv = sliding_window_view(temp_data, WINDOW, 0)
time_midpoint = np.mean(slv[:,-1,:], axis=1)
win_ave_temp = slv[:,2,:]
win_ave_unc = slv[:,3,:]
def moving_ave_frame(df:pd.DataFrame, window:int)->pd.DataFrame:
'Applies a moving average'
slv = sliding_window_view(df, window, axis=0)
moving_averages = np.mean(slv, axis=2)
ma_df = pd.DataFrame(moving_averages,columns=df.keys())
return ma_df
def moving_std_frame(df:pd.DataFrame, window:int)->pd.DataFrame:
'Applies a moving average'
slv = sliding_window_view(df, window, axis=0)
moving_averages = np.std(slv, axis=2)/np.sqrt(window)
ma_df = pd.DataFrame(moving_averages,columns=df.keys())
return ma_df
def lb_ub(values, sigma, factor=1):
lb = values - sigma*factor
ub = values + sigma*factor
return lb, ub
def P1(x, a0, a1):
return a0 + a1*x
fig, ax = plt.subplots(1, 1, figsize = (10, 6))
ave_temp = np.mean(win_ave_temp,axis=1)
ave_unc = np.mean(win_ave_unc, axis=1)
lb, ub = lb_ub(ave_temp, ave_unc)
#Plotting
ax.plot(time_midpoint,
ave_temp,
color=colours.durham.ink
)
ax.fill_between(time_midpoint,
lb,
ub,
color = colours.durham.ink,
alpha=0.2
)
ax.set_xlabel('Window Midpoint (Year)')
ax.set_ylabel('10 Year Moving Average of \n \
Land Average Temperature Anomaly $(^{\circ}C)$'
);
Predictions#
Global temperatures provide an interesting case study for a further introduction to predictive modeling.
There has already been substantial warming compared to the period from \(1850-1900\). This period is set as a pre-industrial baseline[SMH+17]. Further temperature rises will continue to increase the occurrence of extreme weather events and myriad other consequences, with an entire IPCC report dedicated to the consequences of warming over \(1.5^\circ C\). The special report on emission scenarios(SRES)[NAD+00] produced by the IPCC in 2000, details multiple families of emission scenarios with their associated warming.
These scenarios are developed using six independent models. Such models use economic driving forces and predict the consequences of changing macro-economic behavior, for example, the percentage of fossil fuel used compared to renewables.
These highly detailed models are not suitable for this section. Using \(\text{CO}_2\) concentration, a simple model can be formed to determine the change in temperature over the next 30 years. The three scenarios that will be investigated are approximations of the A1 and B1 storylines described from page 247 onwards in the SRES.
A1B) Continued growth in emission Rates. This scenario represents a growth-focused world with a balanced mix of energy sources.
A1T) Net-zero by 2030, no further reductions. This scenario corresponds to a growth-focused world with renewable energy sources.
B1) Net-zero by 2030, and then reducing total atmospheric carbon at the same rate it is currently produced. Corresponding to a global focus on emissions reduction. The relationship between \(\text{CO}_2\) concentration used is:
Where \(C\) is the concentration of \(\text{CO}_2\) and \(S\) is a fitted sensitivity factor.
Current Warming trend#
trend_data = temp_data[temp_data['dt'] > 1960]
trend_ave = moving_ave_frame(trend_data,WINDOW)
lb, ub = lb_ub(trend_ave['monthly_anomaly'],
trend_ave['monthly_anomaly_unc']
)
trend_ave.to_csv(f'../output_files/temperature_{int(WINDOW/12)}'\
'_moving_average.csv'
)
trend_fit, trend_error = curve_fit(P1, trend_ave['dt'],
trend_ave['monthly_anomaly'],
sigma=trend_ave['monthly_anomaly_unc']
)
gradient_lb, gradient_ub = lb_ub(trend_fit[1], trend_error[1,1])
lb, ub = lb_ub(trend_ave['monthly_anomaly'],
trend_ave['monthly_anomaly_unc']
)
#Plotting
fig, ax = plt.subplots(1,1, figsize=(10, 6))
time = np.linspace(2017.3, 2055, 300)
trend_lb = trend_fit - np.diagonal(trend_error)
trend_ub = trend_fit + np.diagonal(trend_error)
plt.fill_between(trend_ave['dt'], lb, ub, alpha=0.2,
color=colours.durham.ink)
plt.plot(trend_ave['dt'], trend_ave['monthly_anomaly'],
c=colours.durham.ink,
label='Moving Average')
plt.plot(time, P1(time, *trend_fit),
linestyle='--',
color=colours.durham.ink,
label='Linear Trend')
ax.set_xlabel('Window Midpoint (Year)')
ax.set_ylabel(f'{int(WINDOW / 12)} Year Moving Average of \n' \
r'Land Average Temperature Anomaly $(^{\circ}\textrm{{C}})$'
)
#Warming Targets
x = np.linspace(1960,2055,100)
y = np.ones_like(x)
plt.plot(x, y*1.5, color=colours.durham.red,
label='$1.5^\circ C$ Warming',
linestyle='--'
)
plt.plot(x, y*2, color=colours.durham.red,
label='$2.0^\circ C$ Warming',
linestyle='-.'
)
plt.fill_between(time, P1(time, *trend_lb),P1(time, *trend_ub))
plt.legend();
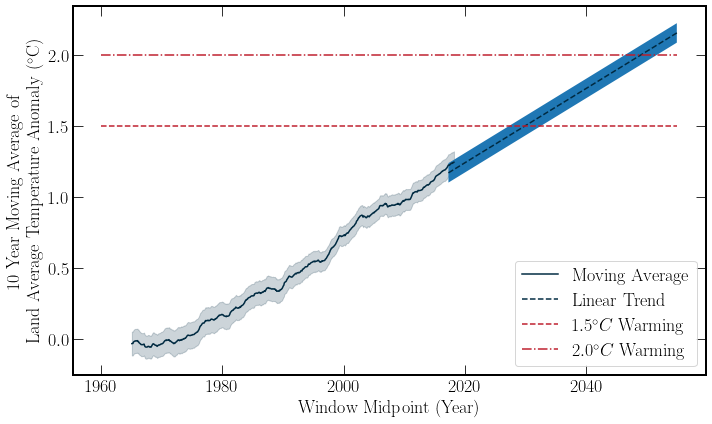
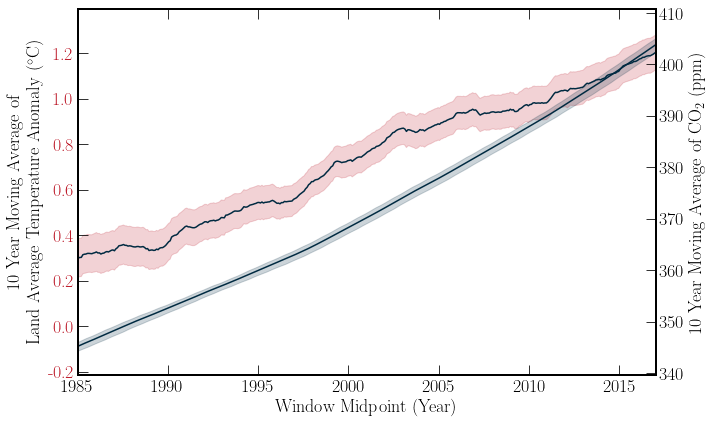
With a simple linear extrapolation of the Berkeley Earth temperature data, one can see that if the current rate of warming persists, then keeping the Global Temperature anomaly below \(1.5^\circ C\) is unlikely, moving into the future. However, this simple model is just for getting a feeling of the data. By combining this dataset with the Global \(\text{CO}_2\) data, the correlation of these datasets can be examined. Both of the datasets’ moving averages are plotted below for a visual comparison. Further, the Pearson correlation co-efficient \((r)\) can be calculated for the datasets. \(r\) is given by,
Where \(\bar{q}\) indicates the mean of \(q\). The \(r\) value can be calculated for the global \(\text{CO}_2\) concentration and the temperature by taking both variables evaluated simultaneously in time.
Note
The error bars on the \(\text{CO_2}\) concentration are two times the standard error on the mean. However, the error bars on the temperature is the mean of the uncertainty over the window. This is because the uncertainty corresponds to 95% of recorded percentages.
co2_slice = np.where((1985 < trend_co2_ave['decimal']) & \
(trend_co2_ave['decimal'] < 2016)
)
temp_slice = np.where((1985 < trend_ave['dt']) & \
(trend_ave['dt'] < 2016)
)
bound_co2 = trend_co2_ave['average'].iloc[co2_slice]
bound_temp = trend_ave['monthly_anomaly'].iloc[temp_slice]
r_coef = stats.pearsonr(bound_co2,np.array(bound_temp)[1:])
print(f'Pearson Correlation Coefficient:{r_coef[0]:.2}');
Pearson Correlation Coefficient:0.99
As expected the two quantities are very strongly correlated. The Pearson correlation coefficient in this scenario is not particularly useful. The information it provides is redundant with the above graph. However, with high dimensional data, a correlation matrix can glean insight into the relationship of variables. A short medium article on correlation matrix plots can be found here